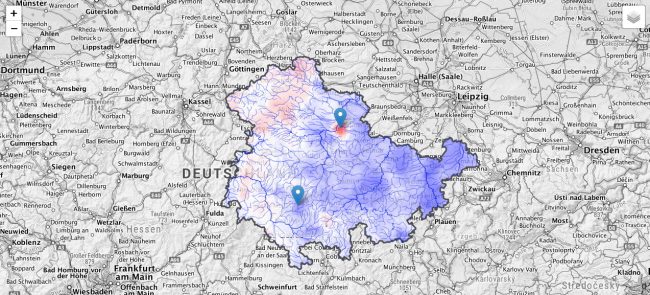
Im Rahmen des TASK-Projekts beschäftigen wir uns unter anderem mit der Berechnung von hydrometeorologischen Indizes, wie dem Standardized Precipitation Index (SPI), die dabei helfen können, Trockenperioden zu erkennen und zu analyiseren.
Dank frei verfügbaren Daten und Software ist es möglich, den SPI für ganz Deutschland flächendetailliert, aktuell und rückwirkend bis 1931 zu berechnen und in einer interaktiven Webanwendung bereitzustellen. In diesem Artikel wird der technische Entwicklungsprozess und die dabei verwendeten verschiedenen Datenquellen und Softwarekomponenten beschrieben.
Als Datenquelle für Niederschlagsdaten nehmen wir den Datensatz HYRAS-DE-PRE des DWD:
HYRAS-DE-PRE ist ein Niederschlagsprodukt für Deutschland in einem 1 km x 1 km Raster für den Zeitraum 1931 bis Vortag und basiert auf täglichen Messwerten der Niederschlagshöhe.
Der Datensatz kann beispielweise zur Analyse des vergangenen Klimas, zur Bias-Adjustierung von regionalisierten Klimaprojektionsdaten und als Eingangsdaten für die hydrologische Modellierung verwendet werden.
HYRAS-DE-PRE Datenbeschreibung
Wie viele andere OpenData-Produkte des DWD darf dieser Datensatz entsprechend der „Verordnung zur Festlegung der Nutzungsbestimmungen für die Bereitstellung von Geodaten des Bundes (GeoNutzV)“ unter Beigabe eines Quellenvermerks ohne Einschränkungen weiterverwendet werden.
Die Daten werden in Form von NetCDF-Dateien bereitgestellt. Diese lassen sich in QGIS öffnen und mit dem Plugin RasterTimeseriesManager animieren:
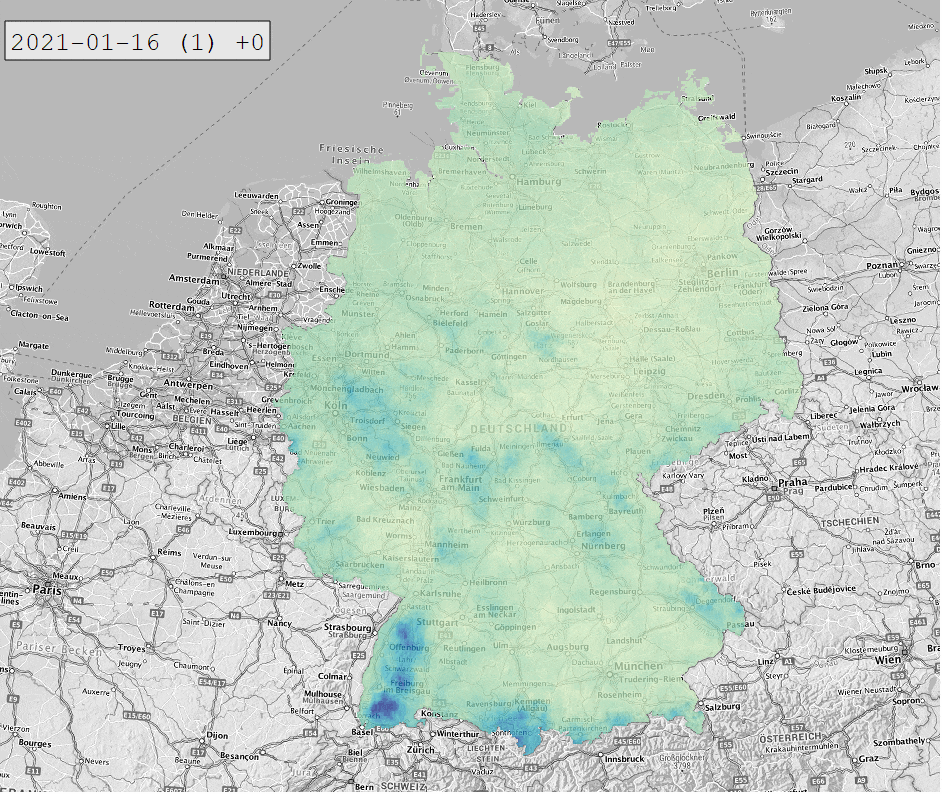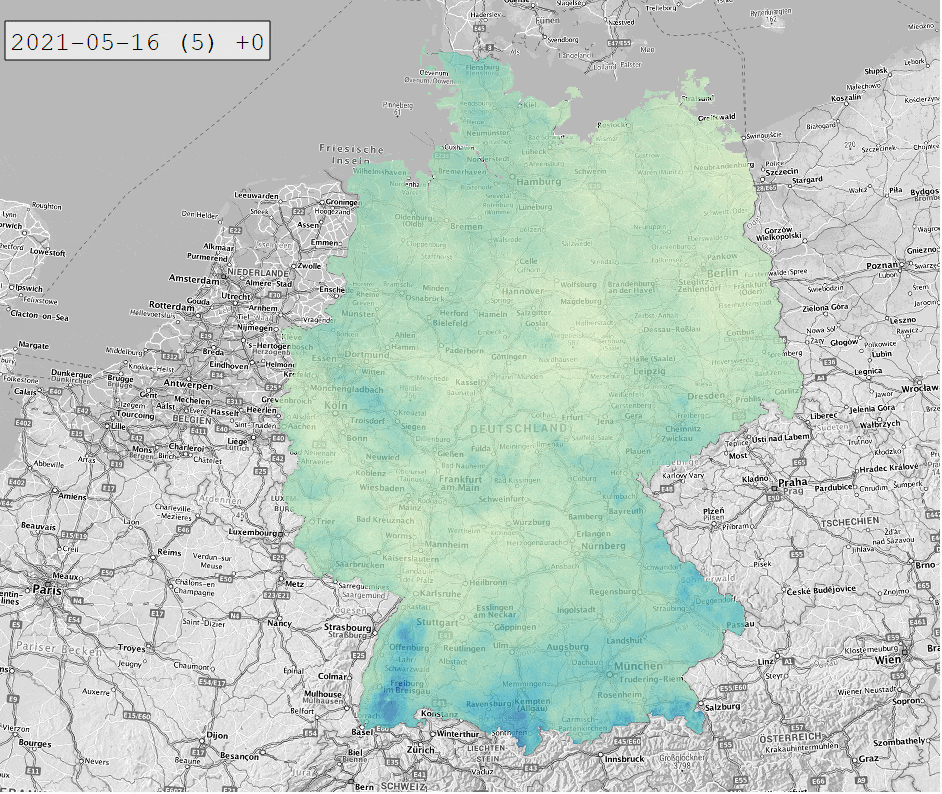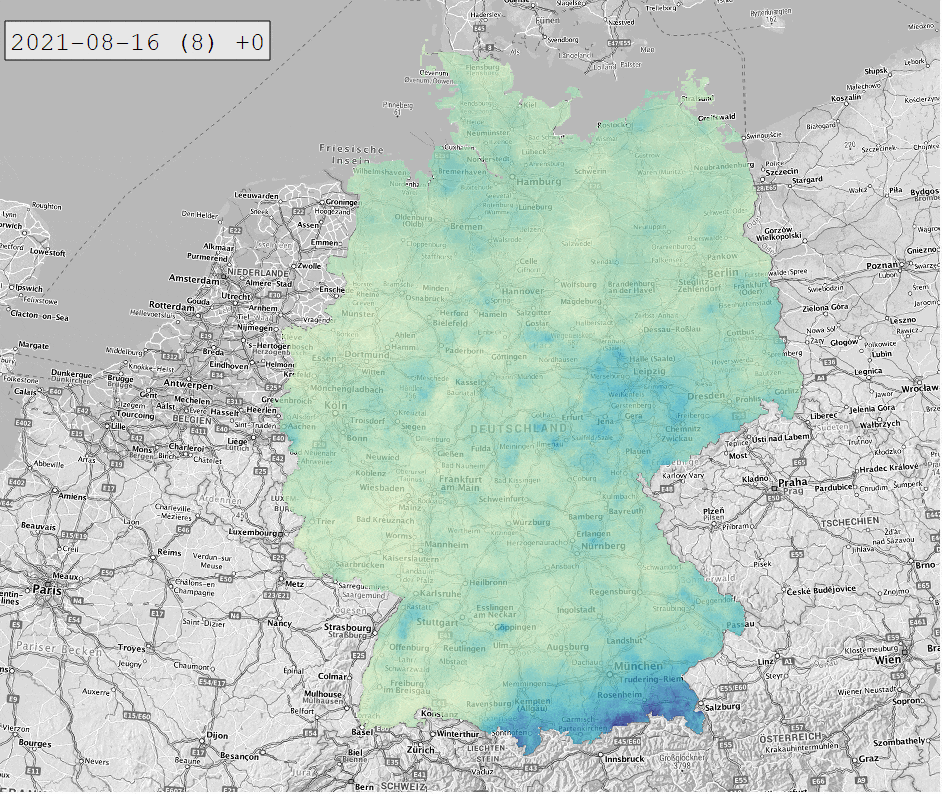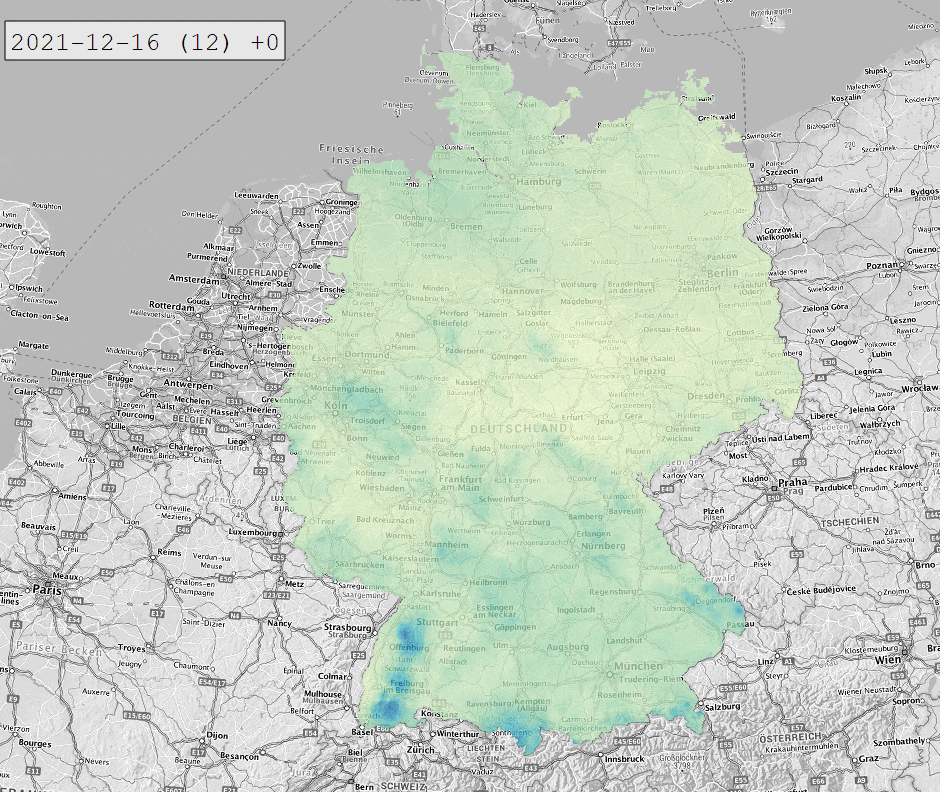
Hinter jeder 1×1 km Zelle der NetCDF-Dateien verbirgt sich eine Zeitreihe des Niederschlags. Um diese zu extrahieren, bedienen wir uns Python mit den Paketen xarray und netCDF4. Das Ganze testen wir in Form eines interaktiven Jupyter Notebooks in Visual Studio Code. So können wir uns anzeigen lassen, wie die NetCDF-Datei strukturiert ist und welche Metadaten (Attributes) hinterlegt sind:
Um für eine bestimmte Koordinate eine Zeitreihe des Niederschlags zu extrahieren, nutzen wir die interp() Funktion von xarray (erfordert scipy). Für die Darstellung als Diagramm genügt der Befehl plot() (erfordert matplotlib):
Für die Beispiele oben haben wir nur eine einzelne Jahresdatei geöffnet und betrachtet. Um mehr als ein Jahr zu verarbeiten, müssen wir mehrere Dateien hintereinander öffnen und diese mit concat() zu einem einzigen xarray Dataset zusammenfügen.
Die Berechnung des SPI-Index führen wir mithilfe von climate_indices durch. Xarray ermöglicht es uns mit apply_ufunc() (und ein paar zusätzlichen Tricks), die Berechnung für alle Zellen des Datensatzes in einem durchzuführen. So erhalten wir ein xarray Dataset mit SPI-Werten von 1931 bis heute für ganz Deutschland in einem 1×1 km Raster. Dieses können wir wieder als NetCDF abspeichern und in QGIS visualisieren. Für die folgende Abbildung wurde für die Indexberechnung eine Zeitskala von 12 Monaten und als Referenzzeitraum 1991-2020 gewählt.
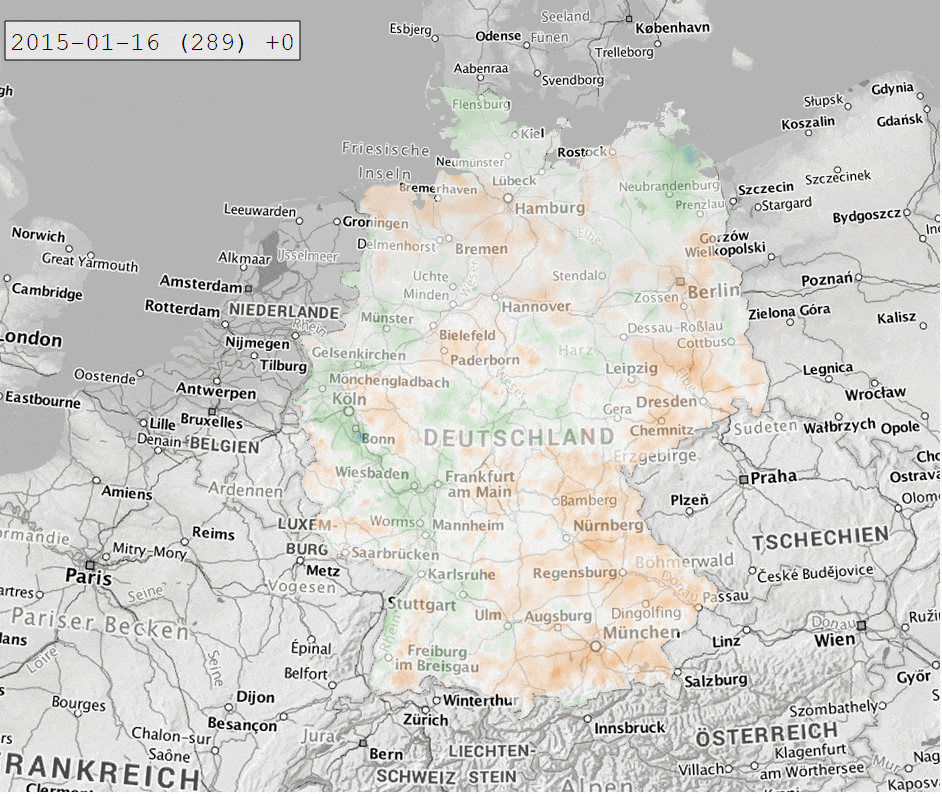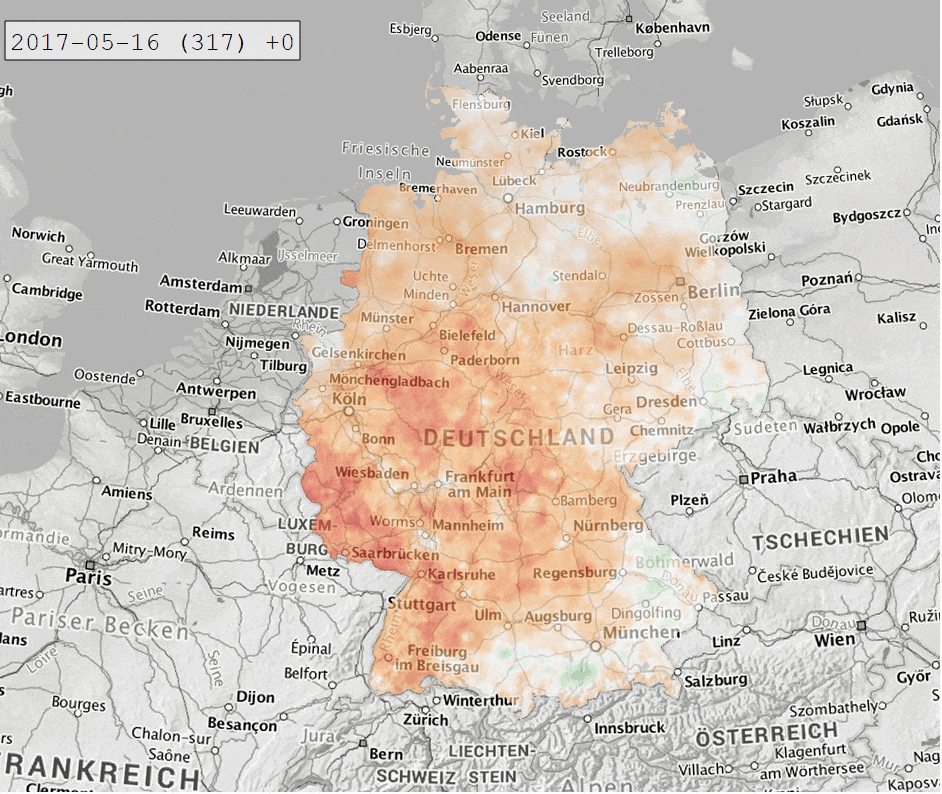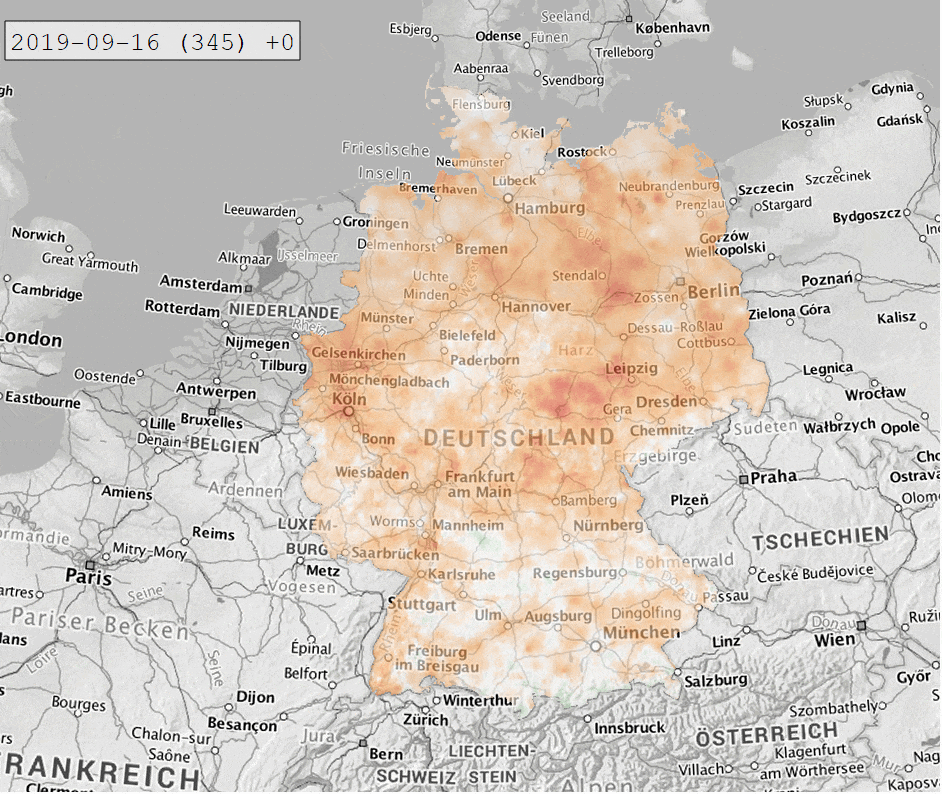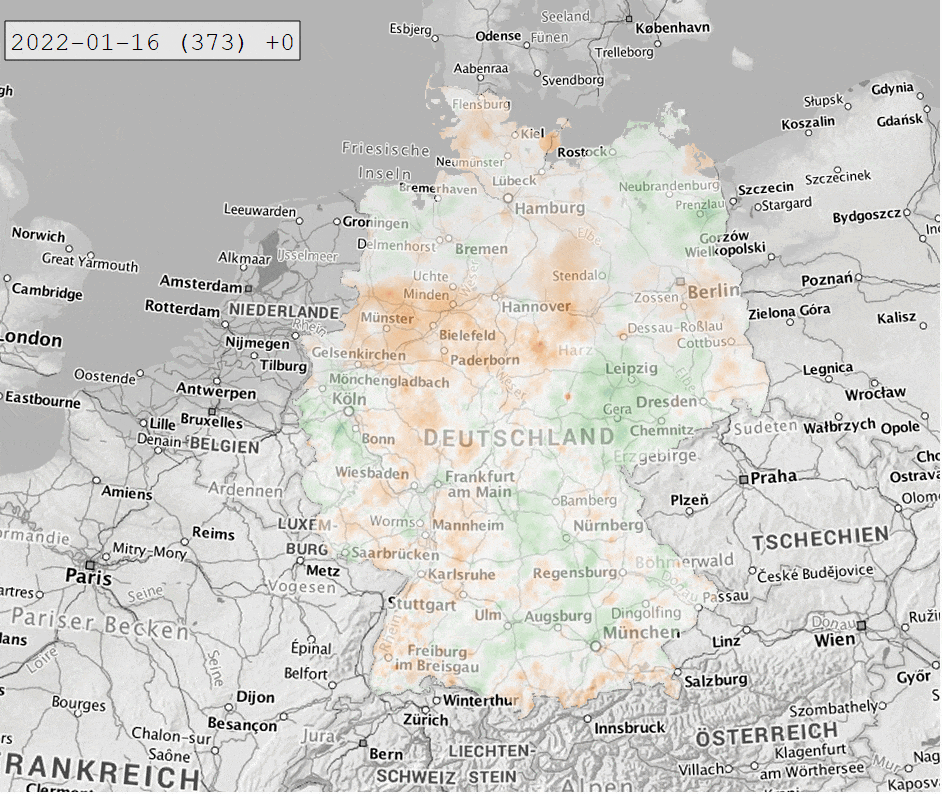
Der letzte Schritt ist diese Daten in einer interaktiven Webanwendung bereitzustellen. Hierzu verwenden wir Dash als Framework, mit Leaflet für die Kartendarstellung und plotly für die Zeitreihenanzeige. Für Layout und Styling kommt bootstrap zum Einsatz.
Für die Webanwendung im TASK-Projekt wurden die Daten noch auf Thüringen zugeschnitten und, um die Darstellung weiter zu beschleunigen, die einzelnen Zeitscheiben vorab als GeoTIFF Raster abgespeichert. Hierbei halfen rasterio und die zugehörige Erweiterung für xarray rioxarray. Für die dynamische Umrechnung zwischen den Koordinatensystemen der Webkarte und den SPI-Daten in der NetCDF-Datei kommt pyproj zum Einsatz.
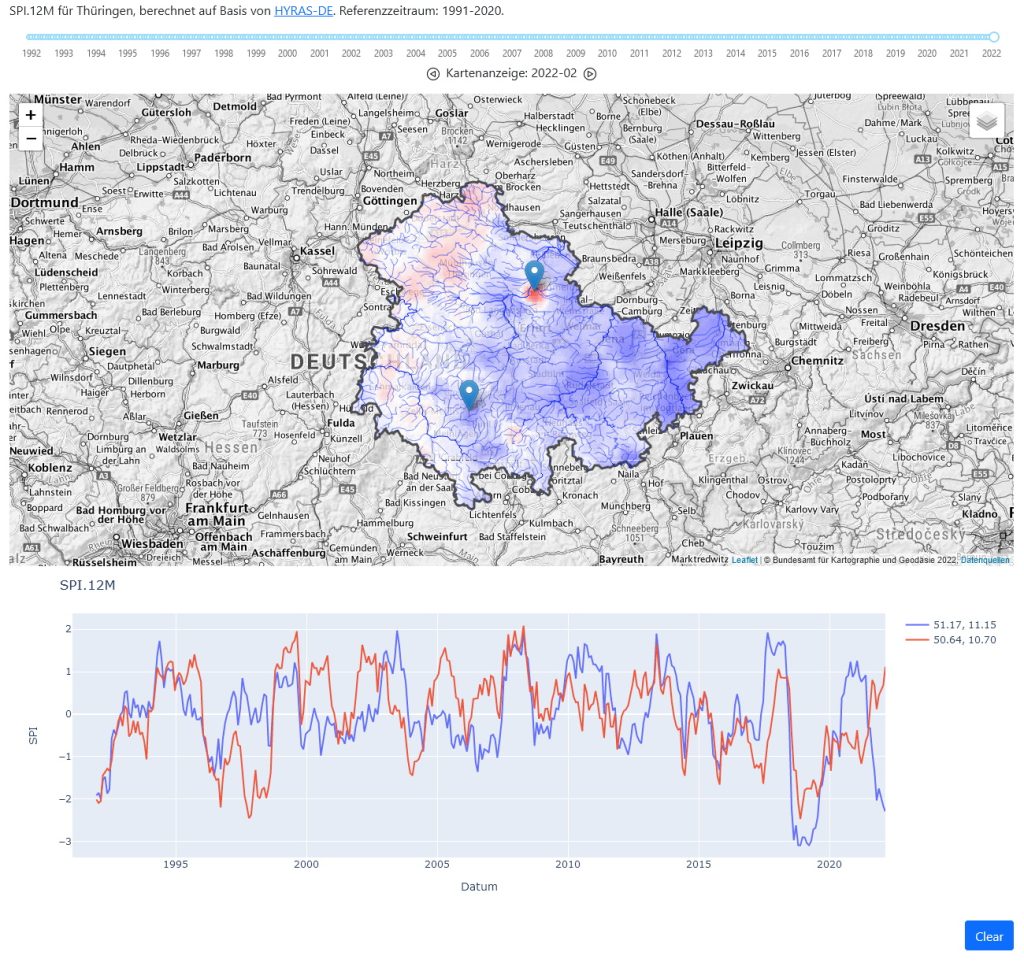
In der Karte werden zur Orientierung Landesgrenzen, Gewässerachsen und -flächen aus dem DLM1000 angezeigt, als Hintergrundkarte wird standardmäßig die TopPlusOpen als WMS-Dienst eingeblendet.
Die Webanwendung wird im weiteren Verlauf des TASK-Projekts um weitere Indizes, Zeitskalen und eine saisonale Vorhersagekomponente erweitert werden.
Der komplette Entwicklungsprozess, angefangen von der Datengrundlage bis zur interaktiven Webanwendung, basiert ausschließlich auf offenen Daten und Open Source Software. Wir danken dem DWD und dem BKG für die Bereitstellung der Daten und den vielen Open Source Entwicklern für ihre Entwicklungsarbeit. SYDRO unterstützt Open Source Software und trägt regelmäßig aktiv zu dessen kontinuierlicher Verbesserung bei.
Weitere, im Artikel nicht explizit erwähnte, aber im Entwicklungsprozess und der Erstellung dieses Artikels genutzte Open Source bzw. freie Software: